


 21.11.2023
21.11.2023  0
0  3 552
3 552 Возникновение искусственного интеллекта (ИИ) и глубокого обучения стало двигателем развития TensorFlow, открытой библиотеки ИИ, которая позволяет строить модели с использованием графов потока данных. Если вы стремитесь к карьере в области ИИ, знание основ TensorFlow является ключевым.
Необходимые условия для обучения TensorFlow
Важно иметь хорошие знания какого-либо языка программирования, предпочтительно Python. Также важно иметь понимание машинного обучения для освоения примеров и использования в практике.
Прежде чем перейти к пониманию, что такое TensorFlow, полезно ознакомиться с глубоким обучением и его библиотеками.
Что такое deep learning
Deep learning (глубокое обучение) является подразделом машинного обучения и функционирует по аналогии с структурой и функциями человеческого мозга. Оно изучает данные, которые являются неструктурированными, используя сложные алгоритмы для обучения нейронной сети.
В основном в глубоком обучении мы используем нейронные сети, основанные на искусственном интеллекте. Здесь мы обучаем сети распознавать текст, числа, изображения, речь и так далее. В отличие от традиционного машинного обучения, здесь данные гораздо более сложные, неструктурированные и разнообразные, такие как изображения, аудио или текстовые файлы. Одним из основных компонентов глубокого обучения является нейронная сеть, которая обычно выглядит как изображение, показанное ниже:
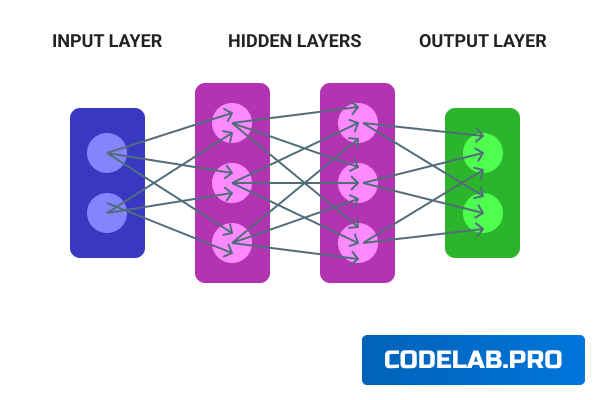
Как видно выше, есть входной слой, выходной слой, и между ними несколько скрытых слоев. Для любой нейронной сети должен быть как минимум один скрытый слой. Глубокая нейронная сеть - это та, у которой есть более одного скрытого слоя.
Давайте подробнее рассмотрим различные слои.
Входной слой
Входной слой принимает большие объемы данных в качестве входа для построения нейронной сети. Данные могут быть представлены в виде текста, изображений, звука и т. д.
Скрытый слой
Этот слой обрабатывает данные, выполняя сложные вычисления и осуществляя извлечение признаков. В рамках обучения эти слои имеют веса и смещения, которые непрерывно обновляются до завершения процесса обучения. Каждый нейрон имеет несколько весов и одно смещение. После вычислений значения передаются на выходной слой.
Выходной слой
Выходной слой генерирует предсказанный вывод, применяя соответствующие функции активации. Выход может представлять собой числовые или категориальные значения.
Например, в приложении классификации изображений он сообщает нам, к какому классу может принадлежать конкретное изображение. Входом могут быть несколько изображений, таких как коты и собаки. Вывод может представлять собой бинарную классификацию, например, число ноль для собаки и число один для кота.
Сеть может быть расширена с использованием множества нейронов на выходе для определения большего количества классов. Также она может использоваться для решения задач регрессии и временных рядов.
Для разработки приложения глубокого обучения необходимо выполнение нескольких предварительных условий. Требуется хорошее знание Python, но также полезно знание других языков программирования, таких как R, Java или C++.
Веса и смещения
В контексте машинного обучения, веса (weights) и смещения (biases) являются параметрами модели, которые определяют ее поведение и способность обучаться на данных.
- Веса (Weights): Веса представляют собой коэффициенты, с которыми умножаются входные данные в модели. Они определяют влияние каждого признака на предсказание модели. В процессе обучения модель настраивает веса таким образом, чтобы минимизировать ошибку предсказания на обучающих данных.
- Смещения (Biases): Смещения - это константы, которые прибавляются к взвешенной сумме входных данных и их весов. Они позволяют модели сдвигаться от нулевого значения, что важно для адаптации к различным условиям и компенсации возможных систематических ошибок.
В линейной модели, как в предыдущем примере, уравнение будет выглядеть так:
y = W * x + bгде
- y - предсказанное значение
- W - веса
- x - входные данные
- b - смещение
В процессе обучения модель подбирает значения весов и смещений так, чтобы минимизировать ошибку предсказания на обучающих данных и обобщать на новые данные.
Пример обучения
Давайте рассмотрим простой пример нейросети для определения написанной на бумаге цифры. Для этого мы будем использовать нейронную сеть с одним скрытым слоем.

Входной слой:
- Каждый пиксель изображения цифры является входным признаком.
- Допустим, у нас есть изображение размером 8x8 пикселей, тогда у нас будет 64 входа (8 * 8).
Скрытый слой:
- Нейроны в этом слое обрабатывают информацию, выявляют паттерны и признаки.
- Давайте представим, у нас есть 128 нейронов в скрытом слое.
Выходной слой:
- У нас 10 нейронов в выходном слое, по одному для каждой цифры от 0 до 9.
- Каждый из этих нейронов выражает уверенность в том, что на входе была определенная цифра.
Процесс обучения:
- Мы предоставляем сети набор изображений с правильно указанными метками (например, "это цифра 5").
- Сеть сначала случайным образом инициализирует свои веса и смещения.
- В процессе обучения она корректирует свои веса и смещения на основе разницы между предсказанным значением и фактическим значением (ошибкой).
- Этот процесс повторяется множество раз для разных изображений, пока сеть не достигнет приемлемого уровня точности.
Что такое Tensorflow
Возникновение искусственного интеллекта (ИИ) и глубокого обучения стало двигателем развития TensorFlow - открытой библиотеки ИИ, разработанной Google. TensorFlow поддерживает создание моделей как для глубокого обучения, так и для традиционного машинного обучения. Эта библиотека, изначально созданная для выполнения крупных числовых вычислений без учета глубокого обучения, оказалась очень полезной для разработки в этой области, что привело к ее открытию.
![]()
TensorFlow принимает данные в форме многомерных массивов более высоких размерностей, называемых тензорами. Эти многомерные массивы удобны для работы с большими объемами данных.
Основой работы TensorFlow являются графы потока данных с узлами и ребрами. Благодаря выполнению кода TensorFlow в виде графов, его легко выполнять распределенно на кластере компьютеров при использовании графических процессоров (GPU).
Почему именно TensorFlow
TensorFlow предоставляет API как на Python, так и на C++, что делает его гибким для разработчиков. Библиотека упрощает создание и конфигурацию нейронных сетей, не требуя сложного программирования. Она также интегрируется с Java и R.
Одним из ключевых преимуществ TensorFlow является поддержка как центральных процессоров (CPU), так и графических процессоров (GPU). Использование GPU ускоряет вычисления, что особенно важно для сложных операций глубокого обучения с большими объемами данных.
TensorFlow также обладает более быстрым временем компиляции по сравнению с некоторыми другими библиотеками глубокого обучения, такими как Keras и Torch.
Как TensorFlow работает
Тензор
Tensor, или тензор, является основным компонентом фреймворка TensorFlow. Все вычисления в TensorFlow осуществляются с использованием тензоров - это матрицы n-мерности, представляющие различные типы данных. Тензор может быть результатом вычисления или происходить из входных данных.
Давайте представим, что у нас есть простой тензор, представляющий изображение в оттенках серого. Это изображение может быть представлено в виде двумерной матрицы, где каждый элемент матрицы представляет интенсивность цвета для каждого пикселя. В этом случае, мы имеем двумерный тензор.
Тензор (изображение в оттенках серого):
[[10, 20, 15],
[15, 25, 30],
[12, 18, 22]]Здесь каждое число представляет интенсивность серого для соответствующего пикселя. Это простой пример тензора с двумя размерностями.
Если у нас было бы цветное изображение, то у нас уже был бы трехмерный тензор, где каждая матрица представляла бы отдельный цвет (красный, зеленый, синий).
Граф
Давайте представим простой граф, который выполняет операцию сложения и умножения. У нас есть два входных значения a и b, и мы хотим получить результат операций c и d:
a -----\
+----- c
b -----/
\
*----- dВ этом графе:
- a и b - входные данные (тензоры).
- + - операция сложения, создающая результат c (тоже тензор).
- * - операция умножения, создающая результат d.
Программные элементы в Tensorflow
В TensorFlow программирование немного отличается от стандартного. Даже если вы знакомы с языком программирования Python или программированием машинного обучения в scikit-learn, это может показаться вам новым концептом.
Обработка данных внутри программы в TensorFlow немного отличается от того, как это делается в обычных языках программирования. В программировании для всего, что меняется, обычно создается переменная. Однако в TensorFlow данные могут храниться и обрабатываться с использованием трех основных элементов:
- Константы (Constants): Имеют постоянное значение, которое нельзя изменить в процессе выполнения. Используются в определении статических значений, таких как параметры модели, гиперпараметры. Нужны для задания постоянных величин в программе.
- Переменные (Variables): Используются для хранения изменяемых значений, таких как веса и смещения в процессе обучения моделей. Нужны для подстраивания параметров модели в процессе обучения.
- Заполнители (Placeholders): Используются для передачи данных в граф во время выполнения, позволяя вам подставлять различные значения в процессе обучения или выполнения модели. Нужны для эффективной передачи внешних данных внутрь модели.
Константы
Константы в TensorFlow - это параметры с постоянными значениями, которые не изменяются в процессе вычислений. Для определения константы используется команда tf.constant().
Пример:
x = tf.constant(5, tf.int32)
y = tf.constant(10, tf.int32)
print(x, y)Переменные
Переменные в TensorFlow позволяют добавлять новые обучаемые параметры к графу. Для определения переменной используется команда tf.Variable(), и ее необходимо инициализировать перед выполнением графа в сессии.
# Определение переменных
W = tf.Variable([0.3], dtype=tf.float32)
b = tf.Variable([-0.3], dtype=tf.float32)
# Определение заполнителя (placeholder)
x = tf.placeholder(tf.float32)
# Линейная модель
linear_model = W * x + bВ этом примере создаются переменные W и b с использованием TensorFlow. Затем определяется заполнитель x, представляющий входные данные. Линейная модель linear_model строится на основе этих переменных и входных данных.
Заполнители
Заполнители (Placeholders) в TensorFlow предоставляют возможность передачи данных в модель TensorFlow извне. Они позволяют присваивать значения позже. Для определения заполнителя используется команда tf.placeholder().
Пример:
a = tf.placeholder(tf.float32)
b = a * 2
with tf.Session() as sess:
result = sess.run(b, feed_dict={a: 3.0})
print(result)Заполнители - это особый тип переменных, используемых для ввода данных из внешних источников. Когда выполняются вычисления, часто требуется загрузка данных из локального файла, изображения, CSV-файла и т. д. Заполнители обеспечивают возможность пошагового ввода данных, что полезно для эффективного управления памятью.
Для передачи значений в заполнитель используется словарь feed_dict, который указывает тензоры, предоставляющие значения для заполнителя.
Сессия
Сессия запускается для оценки узлов. Это называется TensorFlow Runtime.
Пример:
a = tf.constant(5.0)
b = tf.constant(3.0)
c = a*b
# Запуск сессии
sess = tf.Session()
print(sess.run(c))При создании сессии вы запускаете определенное вычисление, узел или операцию. Каждая переменная или вычисление, которое вы выполняете, подобно операции на узле в графе. Изначально граф будет стандартным. В момент создания объекта TensorFlow есть стандартный граф, который не содержит никаких операций или узлов. В тот момент, когда вы присваиваете переменные, константы или заполнители, каждый из них известен как операция (в терминах TensorFlow).
В нашем примере для первых трех команд вы просто создаете граф, и выполнение не происходит до тех пор, пока вы не создадите сессию (с помощью команды sess = tf.session()).
Комментарии
0